A Primer to Big Complex Distributed Systems

Space shuttles, telecommunication networks, and even ride-sharing applications are home to big and complex systems. These systems employ thousands of software developers on different teams. Although big systems don’t have an exact scientific definition, we will refer to systems with a few computer services working together as big systems.
Design Considerations
Big complex systems can be designed to be fault-tolerant, meaning one part deviating from the expected behavior doesn’t necessarily cripple the rest of the system. They can also be self-healing, i.e., the system’s services can auto-recover without requiring manual intervention after some unexpected scenario causes them to deviate. They can also be idempotent, meaning that running the input through the system many times doesn’t alter the system’s state any more than running the same input the first time.
These systems can be stateless, meaning any instance of the service can handle any input, or contrastingly stateful, meaning that some instances are dedicated to handling a subset of the inputs. We can always scale a stateless service without the headache of coordination, which is discussed at length later in the article.
Business Requirements: Functional and non-Functional
Software systems must meet functional requirements, meaning they should do exactly what they’re designed to do. Take Uber, for instance; you expect a driver to arrive within the ETA given by the application and exactly where you requested the ride.
These big systems must also satisfy non-functional requirements that include availability, meaning the application should never go down, and scalability meaning the application should be able to handle a very large number of users at the same time. These systems should also satisfy reliability and consistency requirements. Performance (measured by either response time or throughput) is also critical as a request should be served within an acceptable time, say less than a few seconds.
Building Big Systems: Compute vs Data Nodes
Application architects should separate data and control, i.e., data in databases and control logic in compute nodes. Data outlives code, so mixing data and computation becomes a nightmare down the line when we need to modify data models to add new functionality. Optimally, the code should be ready to handle both backward and forward compatibility, which means that new code should understand old data and old code should understand new data, which is sometimes tricky.
Compute Node: Microservices Hype
So far, we have referred to the different subsystems as components. The term used in the industry is microservices. These microservices are desirable because they leverage a shared-nothing architecture, which works well with horizontal scaling in case the application developers need to scale the system in the future. Horizontal scaling means that the system can scale up just by adding a few more nodes to the system. Vertical scaling, on the other hand, means beefing up the same node with extra resources. Horizontal scaling is the predominant pattern used in cloud computing.
Designing a microservice is much like designing an application programming interface. Microservices should hide a great deal of implementation detail behind a stable (doesn’t change often) and relatively straightforward abstraction so that we don’t find ourselves with a myriad number of microservices all serving micro-functionality.
They should have a single responsibility to take less cognitive effort to describe, reason about, and develop. We shouldn’t cluster unrelated functionality into one microservice just because it’s convenient. They should avoid accidental complexity, i.e., the complexity that doesn’t arise from the problem to be solved, at all costs.
These different microservices interact together using network calls or queues to meet the business requirements. They should be modular and maintainable. They also should be scalable, i.e., able to serve 10x the traffic with minimal changes in the system design and barely noticeable performance degradation when scaling up the system.
Databases
Microservices use queues, databases, caches, and coordination services to execute their defined behavior. Much like importing an external library when writing a piece of code to utilize other people’s efforts, using a database or a queue simplifies designing services since we rely on their provided guarantees.
We use the term “database” as an all-encompassing term. Almost every data node could be considered a database for our purposes here. Databases come in different types and styles, from relational to document-based and from graph to distributed caches. Some argue that even queues are a kind of database.
Usually, the choice of what database to use depends on the entities involved in the applications, their relationships, and the expected join traffic. Although application code could get around a bad database choice, the tech debt lives on for a very long time. Entities that are best suited for a graph database, for example, can be represented using a relational model with a considerable amount of joins between rows, deteriorating both the developer’s productivity and the database performance.
The module of the database that maps keys, called indexes, to the hard disk is called the storage engine. It’s probably the most interesting part of the internal database design. It’s usually implemented using a log-structured merge tree (LSM) or B-tree for quick access to indexes. In all cases, databases use write-ahead logging(WAL) to write transactions to disk before applying them to the internal data structure (LSM or B-tree). Databases use WAL to restore the state of the system in case of a crash.
Some databases grant ACID (atomic, consistency, isolation, and durability) guarantees for transactions. Atomic means “all or nothing” when a user groups a few operations together. Consistency highly depends on the application’s definition of it. Isolation means that a transaction executes separately and independently from every other transaction. Durability means that changes are persisted to disk (or replicated to different nodes) before acknowledging the success to the application.
Database Anomalies and Isolation Levels
Database anomalies result from the way the applications work and the isolation level that the database provides. For some applications, these anomalies could logically never happen, so using a database with weaker guarantees would result in better performance. Examples of anomalies include:
- Dirty reads: A transaction reads a record that has been modified by another transaction and not yet committed.
- Dirty writes: A transaction writes a record that has been modified by another transaction and not yet committed.
- Nonrepeatable reads: A transaction reads the same record twice and gets different results throughout the same transaction.
- Phantom reads: During a transaction, records are added/removed.
- Lost update: A race condition where the outcome results because of a sequence of uncontrolled events that unfolds. For example, a couple of transactions may execute concurrently so that one write overrides the other.
- Write skew: An update transaction based upon stale data.
To deal with some of the anomalies mentioned above, engineers in academia and the industry developed the concept of isolation levels. Although these isolation levels are well understood, it’s advisable to read the documentation of the specific databases multiple times before attempting to use them. Generally speaking, the more guarantees a database provides, the slower operations will be.
- Read committed: Allows for no dirty reads and no dirty writes.
- Snapshot isolation: Writes don’t block reads, and reads don’t block writes. Each transaction is based on a consistent snapshot of the entire database.
- Serializability: Mimics serial execution even if multithreading is used. This isolation mode handles all database anomalies. It’s implemented using:
- Serial execution
- Pessimistic locking: Two-Phase-Locking
- Optimistic locking
Scaling
When a large number of users log onto the application, requests inundate the system. This calls for the system to be scaled either by adding more resources or partial mitigation so that only the bottlenecks are scaled. If the separation between compute nodes and data nodes is honored, then we can only scale the node types that need to be scaled.
Scaling Computation Nodes
Every application contains a set of different workers. This modularity of microservices allows the application developer to scale up and down only those worker-type nodes that need to be scaled.
If a certain worker type is stateless, meaning any node can handle any request, compute nodes are easily scaled by adding more nodes to the pool of nodes serving requests to meet the traffic hitting the system. Auto-scaling rules can be configured so that new nodes are always on-boarded when more users use the system during busy hours. These newly allocated nodes can be removed from the pool of workers during slower times to cut costs.
Scaling compute nodes of stateful applications requires more consideration, but it could be automated too if one is willing to deal with the associated costs and complexity. Coordination is usually needed to determine which nodes get which subset of the traffic. It’s discussed in more depth in the next section.
Coordination
Coordination is a property of stateful systems, systems where specific nodes have to deal with specific requests. It’s not a requirement of the system but a design choice. Writing coordination code is a fairly complex and sometimes daunting job. Some application developers prefer to outsource the coordination problems to a cache, a database, a distributed lock manager, or Zookeeper.
Coordination problems include:
- Electing a leader server (consensus) like in single leader replication
- Crash detection (keeping track of available servers) and service discovery
- Allocating work to nodes like in partitioning
- Distributed lock management
Although there are algorithms to handle consensus like Paxos and Raft, they’re not as straightforward, and implementation can easily incur bugs. Outsourcing coordination to a third-party system (like Zookeeper) makes sense only when one’s budget will not be significantly impacted by the operational and management overhead incurred.
Scaling Data Nodes
Scaling data nodes like databases is a challenge in and of itself because tables can’t continue to grow indefinitely. Many times it’s about writing software that uses data efficiently, other times, it’s about scaling strategies like replication and partitioning.
Although replication and partitioning are stateful operations that themselves rely on coordination, they are the internals of the database, so the implementation details are abstracted away from an application developer using the database as a service.
Replication

All nodes ultimately fail, abruptly and unexpectedly. One way to prevent a single point of failure, which could result in data loss, is to copy all the data from one node to another node. This procedure is called replication, and it provides fault tolerance and redundancy.
Replication also helps with the read traffic performance, as a bonus, since reads can be directed to more nodes, reducing the strain on each node. Although replication is beneficial, its difficulty arises from keeping data in sync with incoming write requests. The three models of replication are discussed briefly below.
Single Leader Replication
This is the predominant model due to its relative simplicity. It’s the model used in PostgreSQL, MySQL, and MongoDB, among many other databases.
Read requests can be directed to any node in the system (called read replicas). Write requests, on the other hand, must be directed to a leader (or master) elected at an earlier point in time. The leader then passes the change stream (replication log) to other nodes. Replication logs can be implemented using different methods like Write Ahead Log or Statement-Based Replication.
Some systems replicate data on different nodes using active anti-entropy or read repair. Active anti-entropy works by comparing Merkle trees, a tree of hashes, between nodes to figure out what subtrees need to be copied from one node to another. Read repair only relies on the read traffic to replicate the data on different nodes. If a record is never read, the data will remain stale indefinitely. Riak gives both options to the user.
Replication lag gives rise to BASE (Basically Available, Soft State, Eventual Consistency) as contrasted to the ACID model discussed earlier in the article. Basically Available means read and write traffic is as available as possible, while soft state means that the state could be a little different from one read replica to another. Eventual Consistency means that eventually (after no additional write traffic), the state will be consistent in all read replicas.
A non-leader node is not critical, and its failure does not affect the state of the system. Leader failover, however, is not straightforward and has to be implemented with care and precision. On detecting the leader’s failure, the read replicas should elect a new leader to take over the cluster. This process of electing a new leader is called “achieving consensus” and depends on coordination between follower nodes, as discussed in a previous section.
Multiple Leader Replication
Network partitions do happen, and they happen extensively. A network partition is when some nodes in the system are disconnected from other nodes in the network. When it happens with a single leader model, writes are blocked.
This gives rise to multi-leader architectures, where a few leaders can handle all of the write traffic. These systems are more complex and require more coordination between the leaders. Although this architecture is more available than single leader replication, writes do require consensus from other nodes, which makes this architecture slower.
Leaderless Replication
With leaderless replication, no node is special. We must write to many nodes (w: write quorum) and read from many nodes (r: read quorum) where w + r > n (n: number of nodes in the cluster) to get consistent data. Although this architecture is more available than the previous architectures, it is easily crippled because of the many acknowledgments required from different nodes in the cluster.
Partitioning

If we have a big database with billions of records, it is virtually impossible to store all the data on one node. We must split the data one way or another on multiple nodes following the horizontal scaling approach to which we are adhering. Each node can have one (or more) partitions.
There are two popular schemes for partitioning (sharding):
- Partitioning by key
- Simple and easy to implement
- Produces “hot spots” where only a limited number of nodes receive most of the traffic
- Range queries are straightforward
- Partitioning by the hash of the key
- The hash function must be consistent between versions for backward compatibility
- Reduces “hot spots” by enabling the traffic to scatter to many nodes more evenly
- Range queries are passed to all partitions like in MongoDB (other databases, like Couch and Riak, don’t support range queries)
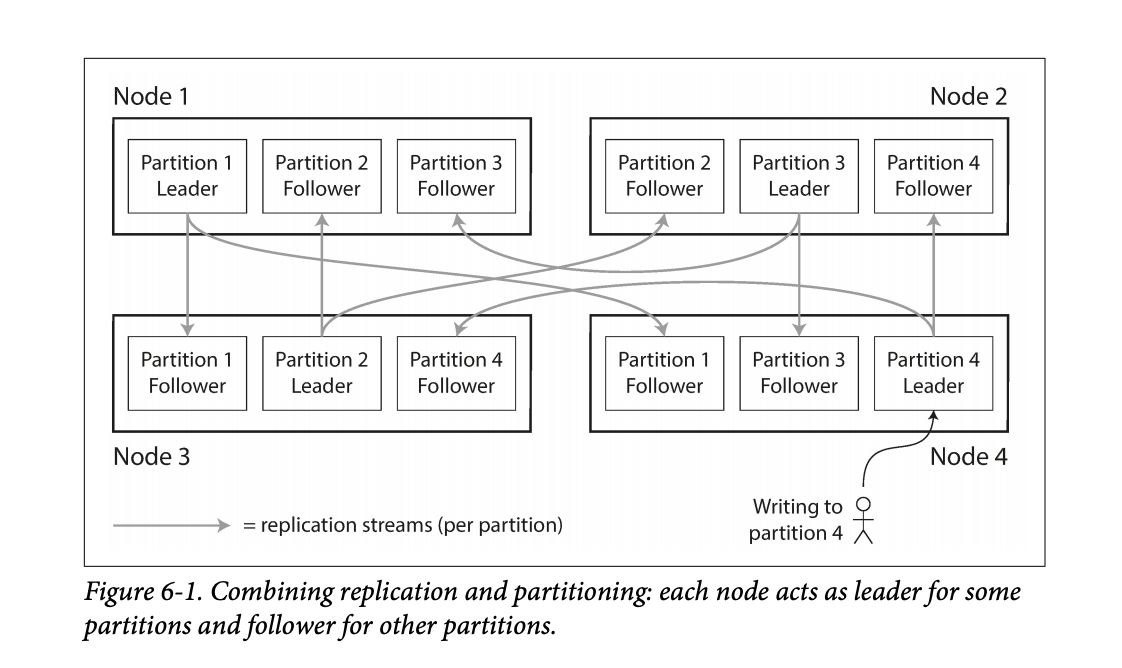
Replication and Partitioning Together
Replication and partitioning go hand-in-hand in a database. Nodes will have different replicas of partitions, as shown in the image below.
Downsides of Commodity Hardware
At the beginning of the article, we mentioned that the common industry standard is to rely on commodity hardware, shared-nothing architecture, and horizontal scaling to build so-called “big complex systems.” This strategic choice doesn’t come without its downsides.
Network Partitioning and Clock Drifts
Since the network is unreliable, it causes many problems that include:
- When network partitioning happens, there’s no good way to differentiate between a packet delay, an overloaded node, or a node crash. The best we can do is use a timeout for a heartbeat to assume a node is down.
- Even with using network time protocol, clock drifts do happen, which means a node can never know the correct time for sure. Clock drifts can cause all kinds of problems, like a leader failing to renew its leadership status or a node having an expired lock and thinking it’s still valid.
Both these problems could cause a split-brain, a malfunction in a single-leader architecture where a leader thinks that it’s the leader when in reality, it’s not anymore due to a token expiration. Split-brain can cause data corruption, but fortunately, a fencing token can be used to safeguard from these incidents.
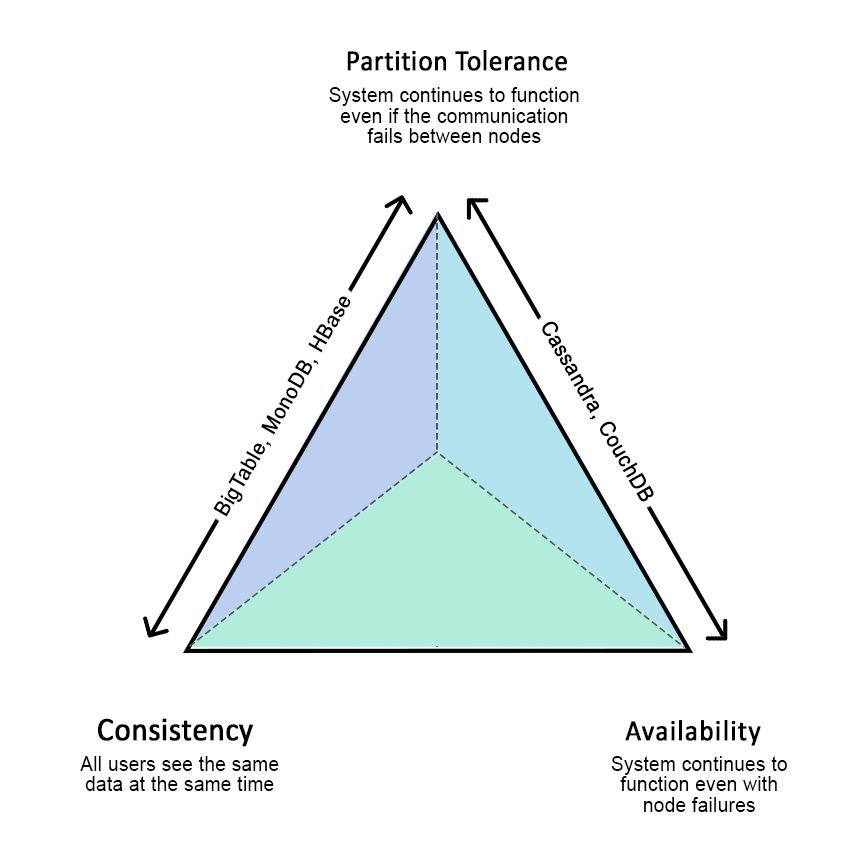
Outdated CAP Theorem
Although outdated, CAP theorem states that in distributed systems, an application developer can only choose from one of two things, consistency or availability, since network partitioning is unavoidable. Consistency is generally a vague term, following Martin Kleppmann, we replace it with the word linearizable, which is a very strong model of consistency.
Linearizability means that if operation B starts after operation A has been completed, operation B must view the same state’s system as having completed A or a newer state. It’s different from serializable since it doesn’t assume concurrent transactions.
Systems can be CP or AP; they could be consistent (linearizable) or available, but not both. Some systems (e.g., social media) sacrifice linearizability for high availability since the user cares more about reaching the social media application than the recency of data. On the other hand, banking applications sacrifice availability for linearizability because an account should never show an inconsistent history of transactions at any point in time.
In the article, we discussed big complex systems with shared-nothing architecture. We described the desired properties we’d like to see in a distributed system, including availability, reliability, and scalability. We went on to discuss the difference between compute nodes and data nodes and the scaling of both types of nodes. We then described coordination, different types of isolation levels, replication, and partitioning. Finally, we touched upon some of the common problems the industry faces when implementing this kind of architecture.
Building a big complex system is an exciting and intellectually stimulating endeavor; you are now well on the way to understanding and even building your own!
If you’re interested in learning more about big systems, check out Martin Kelppmann‘s Designing data-intensive applications.
Appendix
- A node is a single computer (or a device) on the network.
- The state of the system refers to the metadata that the system keeps track of.
- A read request is a piece of information retrieved from a database without altering the system’s state.
- A write request incurs a change in the state of the system.




