A Brief History Of Reinforcement Learning In Game Play

Two years ago, I attended a conference on artificial intelligence (AI) and machine learning. As I was exiting, I came across a talk organized by researchers from a Montreal-based startup called Maluuba, a then-recent acquisition of Microsoft. The researchers demonstrated how they created an AI agent that had achieved the highest possible score of 999,990 in Ms. Pac-Man, the popular arcade game from the 1980s.
The ambiance of excitement and intrigue left everyone in the room speechless. I felt nostalgic; when I was a little boy, cool kids used to win in video games. Nowadays, cool kids write programs to win the games for them.
The researchers attributed their then-recent success to Reinforcement learning (RL). I spent the following few days researching the subject matter. I found mesmerizing ideas of which my rapture today has neither waned nor withered.
In this article, we discuss humanity’s obsession with gameplay problems (be it video games or board games) and why such problems have been unflagging for so long. We briefly mention the niche algorithms, like RL and neural networks (NNs), which have helped to overcome a decades-long impasse.
Games in a nutshell: Actions, Rewards, and States
See, a game has states, rewards, and actions. A gamer generally performs actions to reach a particular state of the game, and along the way, they accumulate some rewards. The final score is the aggregate of all rewards they were able to collect. A “state-space” is a fancy word to indicate all of the states under a particular state representation.
A state is a human’s attempt to represent the game at a certain point in time. It’s not an intrinsic property of the game itself. That’s why a game state can represent different things for different people. For video games, a game state can represent the coordinates of the player in the game’s map, along with the coordinates of treasures and adversaries. Other rich state representations for video games render each video frame as a state.
In Ms. Pac-Man, actions are moving left, right, up, and down. Ms. Pac-Man gets rewards from eating pellets or consuming colored ghosts when he eats a “power pellet.” States represent the position of Ms. Pac-Man, the location and the color of the ghosts at a particular point in time. They also contain information on the current maze shape with the remaining pellets —ones that Ms. Pac-Man hasn’t eaten.
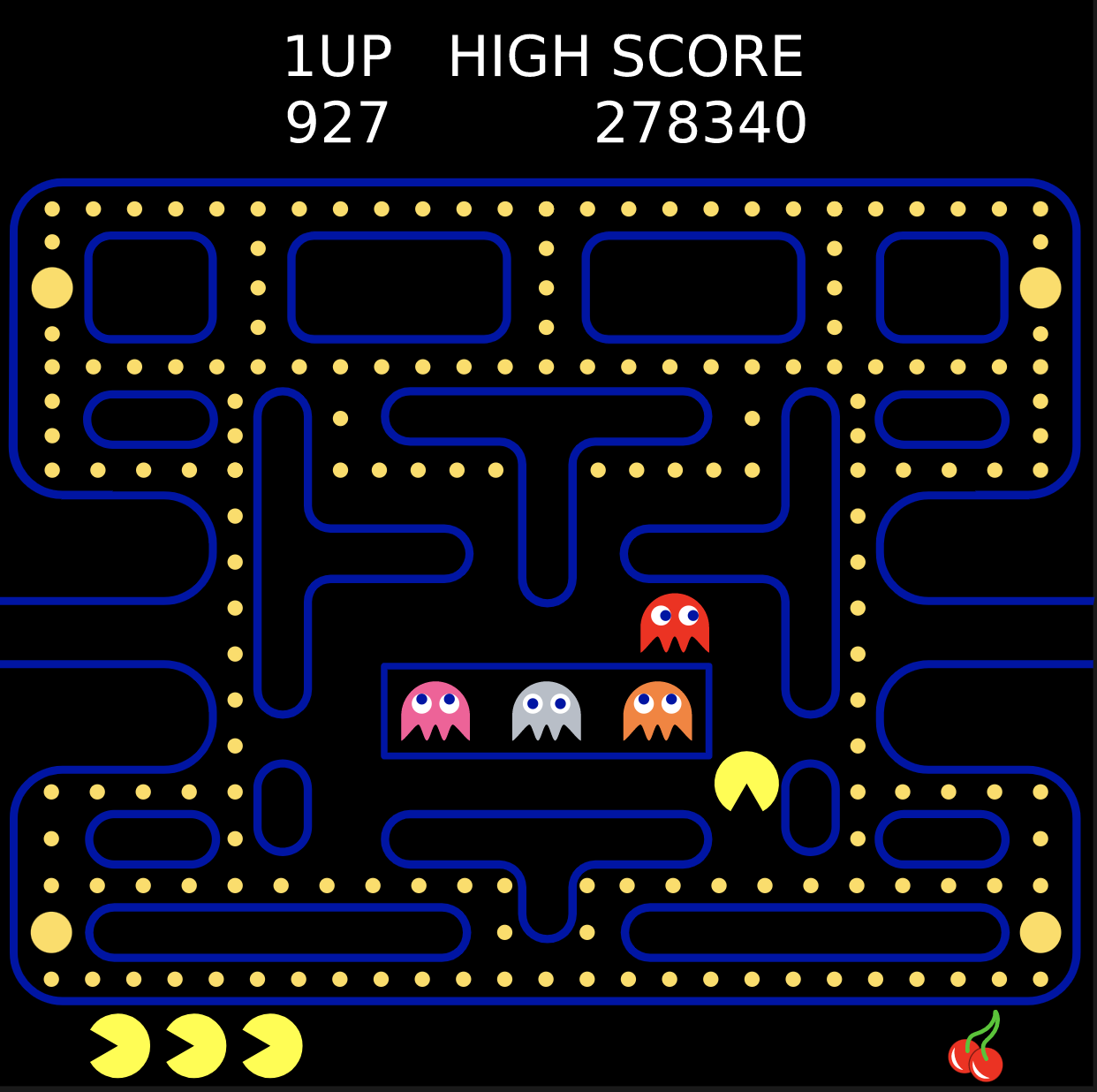
A deadly state (that Ms. Pac-Man should avoid) is when a ghost consumes Ms. Pac-Man. A winning state is when Ms. Pac-Man eats all the pellets and finishes the level.
To give an example from board games, in chess, an action is a move to a piece, be it a knight, a bishop, or any other piece. The state of the game is represented by where all the uncaptured pieces lie on the game board.
Rewards are a little tricky since, throughout the game, a layman can’t say how consequential a move is on the rest of the game. It takes an expert to determine which moves are strategically superior and which player is more likely to win.
Now, this was a non-technical introduction for a Markov Decision Process (MDP) is. It’s a graph of states connected by transitions that have rewards on them. An action is taken at any state to traverse the graph in a way that maximizes the eventual total reward.
Why is gameplay challenging?
Programs that achieve high scores and beat humans in games are hard to create. Perhaps this is one reason why gameplay is popular among dopamine-seeking AI researchers. Recently, programs that are good gamers have used RL models and Neural Networks (NN). They use RL models, which have internal MDP representations, to make sense of the world around them. They use NNs to generalize over states that they’ve never encountered from their current “understanding” of the world.
Now, these RL models are susceptible to some major obstacles like the state representation, the reward architecture problem, and the computational problem (resources like processing time and memory the AI agents consume). We discuss these obstacles more in the next three sections.
The representation problem: What should a game state look like?
See, just like a parent raising a child, researchers asserted that they know better than the agents they created. Rather than having the agents discover the world around them like babies, researchers restricted the detail of game states, crafting them only with a subset of information they deemed relevant.
Richard Sutton, dubbed “father of RL,” shows how this short-term superiority complex has hurt the whole discipline. In his blog “Incomplete Ideas,” he wrote a post titled “bitter lessons,” where he compares utilizing the human understanding of a game to generic searching and learning, with the latter being tremendously more successful.
Time and time again, the agents proved researchers wrong. It turns out that researchers had little idea what parts of the game state AI agents considered useful when attempting to win in a game. Previous reductions in the game space have hurt the agents’ efficiency in ways researchers don’t wholly understand. Humans inject their biases when they pick and choose what features to include in a state.
The reward architecture problem
Board games, like chess, don’t come with a score. In chess, for example, the sole purpose is to capture your opponent’s king. One doesn't get partial credit for capturing a bishop or a knight. The question becomes: How do we evaluate a game state when the game doesn’t have an explicit score in non-terminal states?
A reward function is one that incentivizes an AI agent to prefer one action over other actions. An excellent, yet an unclear incentive, is to win the game. A bad, yet a clear incentive is to capture all of the opponent’s knights. An agent performs best with an incentive that’s clear and effective in both the short-run and the long-run.
A more intuitive example is that a health-conscious person avoids a delicious cheesecake despite the short-term joy it brings just because of the toll it has on their body in the long-run. Similarly, an AI agent using a “good” reward function avoids some short-term gains (captures) for long-term wins.
Historically, chess masters created frameworks to reduce the evaluation of a complex strategy to some numerical values according to the relative values of pieces. For instance, according to one of these frameworks, losing a rook for capturing a queen is a straightforward decision.
However, these frameworks come with a big caveat; they might hurt long-term payoff. For example, capturing a free pawn can give you an advantage (+1) in the short-term but could cost you the lack of a coherent pawn structure, the alignment where pawns protect and strengthen one another, that might prove challenging in the end game. Elements like pawn structures, for instance, aren’t easily quantifiable because they rely on the “style” of the player and their perceived usefulness.
The computational problem: How to search in large state spaces?
In Atari games, the state space can contain 10^9 to 10^11 states. Meanwhile, a game like chess has about 10^46 valid states, whereas a game like Go has 3^361 valid states. To put these numbers in perspective, the number of atoms in the observable universe is 10^82.
Now, although computers have gotten much faster over time, they’re no match for the two major sub-problems: The exploration of the state space and the training of NNs. The exploration problem is trying to visit as many states as possible so that an agent can create a more realistic model of the world.
The training of NNs generalizes the inferences made on the partially observable state-space to the non-observed parts. That is to say, how similar an unvisited state to a visited one. We go into more detail regarding each of the two issues more in the following two sections.
RL and the exploration/exploitation tradeoff
Throughout life, it’s hard to pinpoint how much one “turn” contributed to one’s contentment and affluence. You can’t tell how much joy a job or a relationship brought compared to another job offer you didn’t accept or a suitor you rejected.
The same problem persists in games too. It’s hard to precisely identify the contribution of actions in different stages of the game on the final score. The technical term for such a problem is the “credit assignment” problem. RL has been victorious in disentangling actions worth taking in specific game-states. In return, the credit assignment problem has earned RL its well-deserved fame.
RL models solve the “credit assignment” problem by assigning a credit value to each state. RL works in two interleaving phases — learning and planning. Learning is when the agent is roaming the model to learn about the states. Planning is when the agent assigns credit to every state and determines which actions are better than others.
Planning and learning are iterative processes. In one iteration, after learning — collecting information about the states, the agent performs planning on the RL model. It constructs transitions from one state to another by choosing one that’s bound to maximize future rewards. In the next iteration of learning, when prompted with which action to choose for a particular state, it picks the transitions that lead to terminal states with the maximum final score.
See, only if an agent visits every state, is it able to give states a precise credit value. But as many problems worth solving have incredibly large state spaces, RL agents don’t visit every state. The agent works with only the discovered portion of the world; it approximates the credit for unvisited states based on its “knowledge” of visited states. This approximation requires NNs, which we explain in the next section.
The credit of one state depends on the following states the agent chooses to visit. Typically, an RL model determines the subsequent state to visit (or the action to choose) using the “exploration/exploitation tradeoff.”
When you go to a restaurant and order your favorite dish, you’re exploiting a meal that you already know is good. If you explore a new dish, there’s a risk it’s worse than your favorite dish, but at the same time, it might become your new favorite dish. As the adage goes: “Nothing ventured, nothing gained.”
In gameplay, exploration makes the model probe a much more significant portion of the state space. In contrast, exploitation makes it only probe a limited but promising region of the state-space.
Now, the state-space search problem is defined by how many states an RL model can visit to make better approximations. The more extensive the region, the exploration covers, the more accurate the credit assignment is, and the more robust the model becomes. Yet, trying many actions for one state increases the computational complexity exponentially.
What about Neural Networks?
Since an RL model only looks at a subset of the state-space, it can’t say which action will work best for unvisited states. During a run, the agent might hit some states that it has never seen before. It needs a mechanism to capture similar patterns between states of optimal state-space transitions. Although their training can be quite daunting computationally, NNs are an excellent tool for capturing such patterns.
See, researchers try to mimic the structure of the human brain, which is incredibly efficient in learning patterns. The human brain, however, has 86 billion neurons and 100 trillion synapses. The Hebbian theory attempts to explain the plasticity of the brain: “Neurons that fire together, wire together.”
Donald Hebb explains that persistence or repetition of activity tends to induce lasting cellular changes. For example, driving becomes second nature to someone after a few years because the pathways, or the synapses for a more rigorous term, involved in driving solidify after a few hundreds activations.
In gameplay, researchers use NNs that are malleable enough to make sense of all the different patterns in the state space. At the same time, these NN are sufficiently deep (in terms of layers) to learn all the subtle differences between the transitions in the state space.
RL changed video games gameplay forever
In the early 2010s, a startup out of London by the name of DeepMind employed RL to play Atari games from the 1980s, such as Alien, Breakout, and Pong. This “practical” application caught most of the research community by surprise as at a time, RL was only deemed an academic endeavor. The startup was valued at half a billion dollars and became part of Google. DeepMind’s researchers then published a paper in the popular journal, Nature, about human-level control in Atari games for computers.
Out of the three problems that we described earlier, videogames suffer from the state-space representation and the intensive computations. To overcome the state representation problem, the researchers passed the raw pixels from the video frames as is to the AI agent.
To overcome the computational problem, the researchers utilized a few tricks. They reduced the state-space enumerated by applying downsampling techniques and frame-skipping mechanisms. When it came to the NNs, they skipped hyper-parameters tuning. In non-technical words, they used a neural network and not the best neural network.

Board games had its fair share of success too
The fascination with boardgame gameplay is not a scintilla less captivating. Different board games have various intrinsic properties that affect their state spaces and their computational tractability. Although computers were able to beat humans in games like checkers in the 1960s and chess in the 1990s, “Chinese Go” seemed unwavering, researchers deemed winning “Go” the holy grail of AI.

David Silver, a professor at University College London and the head of RL in DeepMind, has been a big fan of gameplay. After graduating from Cambridge, he co-founded a videogames company. He then returned to academia and did his Ph.D. in gameplay under the supervision of Richard Sutton.
In 2016 while working for DeepMind, Silver, with Aja Huang, created an AI agent, “Alpha Go,” that was given a chance to play against the world’s reigning human champion. 100 million people were watching the game and 30 thousand articles were written about the subject; Silver was confident of his creation. AlphaGo won the match 4-1, a triumph that sparked another wave of excitement regarding RL. The hype over such an AI agent was only befitting. It acquired knowledge about a game that took humans millennia to amass.
Amongst the problems of gameplay we described above, AI agents that play Go suffer from the computational problem and the reward architecture problem. This time, the researchers only enumerated the most likely subset of state-space using Monte Carlo Tree Search (MCTS), thus cutting back on the computationally demanding requirements. The researchers also leveraged distributed computing with a large number of TPUs, custom hardware made specifically to train NNs.
To overcome the reward architecture problem, AlphaGo utilized both model-based learning using MCTS and model-free learning using NNs. The model-free part represents the intuition of the agent, while the model-based represents the long-term thinking.
Alpha Zero and learning all perfect information games
Silver didn’t stop there; he then created another agent Alpha Zero, yet a more potent agent able to play chess, shogi (Japanese chess), and Go. Alpha Zero utilized more aggressively than any of its predecessors “self-play,” i.e., it teaches itself how to play merely by playing against itself many many times and NOT by studying how professional players play.
To test how good AlphaZero is, it had to play against the computer champion in each game. It was able to beat Stockfish, winner of six out of the ten most recent world computer chess championships, and yes, there’s a championship for that. In shogi, it beat Elmo, the top shogi program.
When AlphaZero and AlphaGo went head to head, AlphaZero annihilated AlphaGo 100-0. The difference is simple: AlphaGo was trained on games played by humans, whereas AlphaZero just taught itself how to play. Human knowledge seems to hurt AI agents confirming Sutton’s argument once more.
That AlphaZero was able to master three different games implies that its dominance would extend to any other perfect information game, one where all information about the game is available to all participants of the game. Chess, shogi, and Go are perfect information games, unlike poker or Hanabi, where opponents can’t see each other’s hands.
Conclusion
The potential of AI is immeasurable and will only continue to flourish through a better understanding of neuroscience and an expansion in computer science. Although we’ve described the gameplay problem in this article, it is not an end in itself. Aside from motivating people, gameplay has provided a perfect test environment to develop AI models, generally because they are hard problems. These same models are being utilized in real-life applications like identifying cancer and self-driving cars as we speak. And this is just the beginning, who knows what the real potential or the different applications that these models would be applicable to in the future!





{kind=link}
{kind=link}